1. Gradient Descent의 종류
Stochastic gradient descent
-Update with the gradient computed from a single sample
Mini-batch gradient descent
-Update with the gradient computed from a subset of data
Batch gradient descent
-Update with the gradient computed from the whole data
경사하강법(Gradient Descent)

경사하강법은 비용함수를 최소화하는 방향으로 가중치를 업데이트하는 방법을 의미한다. 이때 비용함수란 데이터의 실제값과 모델의 예측값의 차이를 일컫는다. 학습률(Learning rate)은 하이퍼 파라미터로 임의로 조절하여 학습의 수렴을 유도할 수 있다.
경사하강법을 사용하면 비용함수의 기울기(gradient)를 구한 뒤 이전 가중치의 차를 구하는 방식으로 가중치를 업데이트하게 된다.
모멘텀(Momentum)
원래 모멘텀은 외부의 힘이 없을 경우 계속 운동하던 방향대로 이어나가려는 성질을 의미한다. 바닥에 공을 굴리면 계속 앞으로 나가는 것을 예로 들 수 있다.
딥러닝에서의 모멘텀은 경사하강법에 이러한 성질을 적용한 방식이다.

즉, 모멘텀은 이전에 이동했던 방향과 기울기의 크기를 기억하여 어느 정도 업데이트에 반영을 하게 된다. 모멘텀을 얼마나 반영할지는 학습률과 마찬가지로 하이퍼 파라미터이다.
네스테로프 모멘텀(Nesterov Momentum)
모멘텀은 이전의 방향과 기울기의 크기로 현재의 가중치에 관성을 주게 된다. 하지만 이러한 모멘텀은 오버슈팅(overshooting)의 문제가 있다. 즉 경사가 가파른 곳을 빠르게 내려오다 관성을 이기지 못하고 극소점을 지나쳐버리는 것이다.
이러한 오버슈팅을 해결하기 위해 네스테로프 모멘텀이 개발되었다. 네스테로프 모멘텀은 원래의 모멘텀과 달리 이전의 방향으로 먼저 이동해서 기울기의 크기를 구한 뒤 이를 통해 가중치를 업데이트하는 방식이다.

모멘텀은 속도는 빠르지만 관성에 의해 극소값을 찾지 못할 위험이 있는 반면,
네스테로프 모멘텀은 관성에 의해 이동했을 때의 기울기로 가중치를 업데이트하기 때문에 이러한 모멘텀의 단점을 극복한다.
Adagrad
Adagrad는 Adaptive Gradient의 약자이고 적응적 기울기라고 불린다. 딥러닝에서는 적절하게 학습률을 설정하는 것이 중요하다. 이 값이 너무 작으면 학습 시간이 너무 길어지고, 반대로 너무 크면 발산하기 때문이다.
이러한 학습률을 조절하기 위한 방법으로는 학습률 감소(learning rate decay)가 있다. 학습률 감소는 학습을 진행하면서 학습률을 점차 줄여나가는 방식으로, 매개변수 전체의 학습률을 일괄적으로 줄이게 된다. 이를 더욱 발전시킨 방법이 Adagrad이다.
Adagrad는 개별 매개변수에 적응적으로 학습률을 조절하면서 학습을 진행한다.

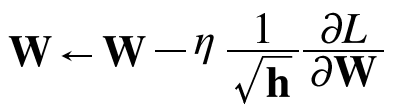
$\frac{\partial L}{\partial x}$: gradient
$\eta$: learning rate
우선 gradient를 element-wise multiplication을 통해 제곱하여 $h$를 구한다. 이때 $h$는 이전까지의 gradient의 누적값이 되고 스칼라가 아닌 행렬로 값이 나오게 된다. 따라서 Adagrad는 각 매개변수의 과거 gradient 값을 활용해 learning rate를 조절하게 된다.
다른 수식을 통해 이를 확인해보자.

위의 수식을 보면 위에는 나와있지 않던 $\epsilon$이 추가되어 있다. 이는 $G_{t}$값이 0이 되었을 때 학습이 잘못되는 것을 방지하기 위해 추가한 것이다.
RMSProp
RMSProp은 AdaGrad의 단점을 보완한 기법이다. AdaGrad는 과거의 기울기를 누적 제곱하여 더하는 방식으로 진행되기 때문에 점차 갱신값이 작아진다. 무한히 학습하면 분모가 계속해서 커져 갱신값이 0에 가까워지는 문제가 생긴다. 이를 개선한 것이 RMSProp이다.
RMSProp은 과거의 기울기들을 똑같이 더하는 것이 아니라 과거의 기울기는 조금 반영하고 최근의 기울기는 많이 반영한다. 이를 지수이동평균(Exponential Moving Average, EMA)라 한다.

수식을 통해 확인해보면 $G_t$가 gradient 제곱의 EMA인 것을 확인할 수 있다. $\eta$는 stepsize가 아니라 learning rate이다.
AdaDelta
AdaDelta는 AdaGrad에서 더 발전된 방법이다. AdaDelta도 동일하게 gradient의 지수 평균을 구한다. 다만, learning rate를 없애고 가중치 $W_t$의 변화량을 이용하게 된다.

Adam(Adaptive Moment Estimation)
Adam은 RMSProp과 Momentum 방식을 결합한 알고리즘이다. Momentum과 비슷하게 지금까지 계산한 기울기의 지수 평균을 저장하며, RMSProp과 비슷하게 기울기의 제곱값의 지수 평균을 저장한다.

이때 m과 v가 처음에 0으로 initialize되어 있다.
reference
https://velog.io/@cha-suyeon/DL-%EC%B5%9C%EC%A0%81%ED%99%94-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98
[DL] 최적화 알고리즘 - SGD, Momentum, Nesterov momentum, AdaGrad
공부 벌레🐛가 되자!계속 볼수록 익숙해져야 하는 개념이 계속 볼수록 잘 모르겠는 경우가 생긴다.🤔 저번주 최적화 알고리즘까지 공부를 마치고 다시 처음부터 되돌아 가서 공부했다. 오늘
velog.io
https://amber-chaeeunk.tistory.com/23
딥러닝) optimizer ( SGD , Momentum , AdaGrad , RMSProp, Adam )
1. Stochastic Gradient Descent (SGD) SGD는 현재 위치에서 기울어진 방향이 전체적인 최솟값과 다른 방향을 가리키므로 지그재그 모양으로 탐색해나간다. 즉, SGD의 단점은 비등방성(anisotropy)함수에서는
amber-chaeeunk.tistory.com
'Naver Boostcamp' 카테고리의 다른 글
| [DL Basic] 최적화 (0) | 2023.08.14 |
|---|---|
| Hand Bone Image Segmentation 프로젝트 대회 (0) | 2023.08.01 |
| 글자 검출 프로젝트 대회 (0) | 2023.08.01 |
| 재활용 품목 분류를 위한 Object Detection 대회 (0) | 2023.08.01 |
| 마스크 착용 상태 분류 대회 (Public 5위, Private 2위) (0) | 2023.04.24 |