1. 프로젝트 설명
1-1. 개요
COVID-19의 확산으로 우리나라는 물론 전 세계 사람들은 경제적, 생산적인 활동에 많은 제약을 가지게 되었습니다. 우리나라는 COVID-19 확산 방지를 위해 사회적 거리 두기를 단계적으로 시행하는 등의 많은 노력을 하고 있습니다. 과거 높은 사망률을 가진 사스(SARS)나 에볼라(Ebola)와는 달리 COVID-19의 치사율은 오히려 비교적 낮은 편에 속합니다. 그럼에도 불구하고, 이렇게 오랜 기간 동안 우리를 괴롭히고 있는 근본적인 이유는 바로 COVID-19의 강력한 전염력 때문입니다.
감염자의 입, 호흡기로부터 나오는 비말, 침 등으로 인해 다른 사람에게 쉽게 전파가 될 수 있기 때문에 감염 확산 방지를 위해 무엇보다 중요한 것은 모든 사람이 마스크로 코와 입을 가려서 혹시 모를 감염자로부터의 전파 경로를 원천 차단하는 것입니다. 이를 위해 공공 장소에 있는 사람들은 반드시 마스크를 착용해야 할 필요가 있으며, 무엇 보다도 코와 입을 완전히 가릴 수 있도록 올바르게 착용하는 것이 중요합니다. 하지만 넓은 공공장소에서 모든 사람들의 올바른 마스크 착용 상태를 검사하기 위해서는 추가적인 인적자원이 필요할 것입니다.
따라서, 우리는 카메라로 비춰진 사람 얼굴 이미지 만으로 이 사람이 마스크를 쓰고 있는지, 쓰지 않았는지, 정확히 쓴 것이 맞는지 자동으로 가려낼 수 있는 시스템이 필요합니다. 이 시스템이 공공장소 입구에 갖춰져 있다면 적은 인적자원으로도 충분히 검사가 가능할 것입니다.
1-2. 클래스 설명

- 사용자의 이미지가 주어지면 마스크 착용 여부, 성별, 나이를 판단하여 총 18개의 클래스를 추론해야 한다.
1-3. 데이터셋 구성
data
├── eval
│ ├── images
│ └── info.csv
└── train
├── images
│ ├── 000001_female_Asian_45
│ │ ├── incorrect_mask.jpg
│ │ ├── mask1.jpg
│ │ ├── mask2.jpg
│ │ ├── mask3.jpg
│ │ ├── mask4.jpg
│ │ ├── mask5.jpg
│ │ └── normal.jpg
│ └── ...
└── train.csv
eval: test 데이터셋
-images: 12600개의 이미지 폴더
-info.csv: inference
train: train 데이터셋
-images: 18900개의 이미지 폴더
-train.csv: 2700명의 신상 정보- 모든 데이터셋은 아시아인 남녀로 구성되어 있고 나이는 20대부터 70대까지 다양하게 분포되어 있음
- 전체 사람 명 수 : 4,500
- 한 사람당 사진의 개수: 7 [마스크 착용 5장, 이상하게 착용(코스크, 턱스크) 1장, 미착용 1장]
- 이미지 크기: (384, 512)
1-4. 평가 방법
- 학습 데이터 60%, public 데이터 20%, private 데이터 20%
- f1 score, 'macro'

1-5. 대회 결과 요약


Public 5등, f1 socre 0.7660 → Private 2등, f1 score 0.7668
- public score에 비해 private score가 상승하며 높은 일반화 성능을 보였습니다.
2. 프로젝트 팀 구성 및 역할
공동 역할: Backbone 모델 리서치, 모델 성능 실험
내 역할: EDA, resnext50 모델 설계 inference EDA, 최종 모델 앙상블 구성 등
3. EDA
- mask: 마스크 착용여부는 개수가 동일
- gender: 여성(1658)이 남성(1042)보다 많다.
- age: 데이터 설명에는 70대까지 존재한다고 적혀 있었지만, 학습 데이터는 18 ~ 60의 범위. 그중 60세 이상은 60세 뿐이고, 전체의 약 0.1%(192)에 불과하여 불균형 문제가 굉장히 심각함.
4. 프로젝트 진행 과정
4-1. 모델링 중요 point
4-1-1. Validation 기준 설정
문제1. validation 지표의 신뢰성이 떨어짐
- 학습할 수록 validation score는 상승하지만 test score는 하락함
- validation 데이터 분포와 test 데이터 분포가 다를 수 있음을 추측

해결1. 자체 validation 기준(epochs=3, early stopping=1)
- 일반적으로 에폭 3회까지 val loss가 떨어지다가 4회에 크게 상승하는 패턴
- 그 이전에 학습이 종료되었을 때 좋은 test score
- 이후 학습하면 val loss는 하락하지만 test score는 떨어짐. → 과적합 발생
문제2. 기존 데이터셋을 이미지 별로 구분할 시 Train-Dataset과 Validation Dataset에 같은 사람이 포함됨.
- 위 경우 학습 시 학습할 수록 Validation Score가 항상 높게 나오는 문제점 발생
해결2. 데이터셋을 이미지 별이 아닌 사람 별로 구분하는 Dataset을 구성
- 같은 사람이 포함되지 않고, 라벨이 균일하게 나뉘도록 train set과 validation set을 분할함.
- 실제 test score와 비슷한 신뢰성 있는 validation score를 측정할 수 있었음
4-1-2. 라벨 불균형
문제1. 성별 불균형
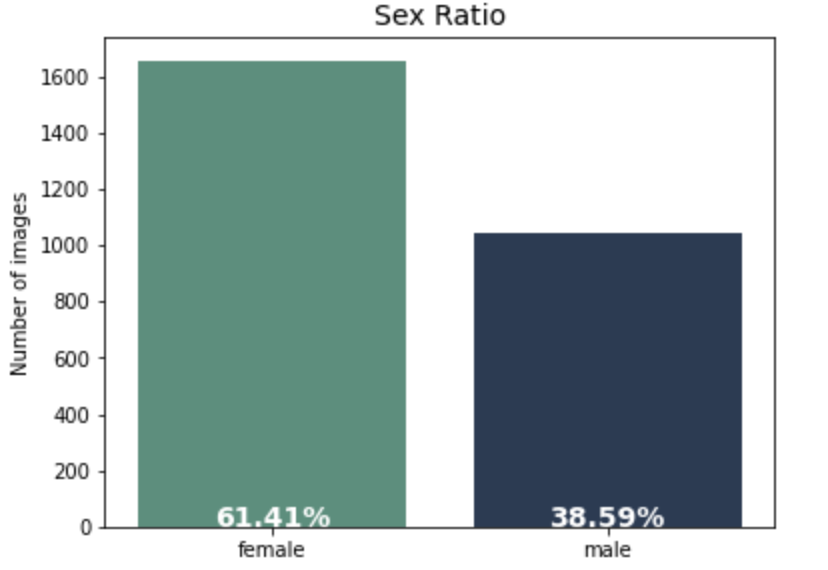
- gender: female(1658) > male(1042)
문제2. 연령 불균형


- age: 18 ~ 60의 범위. 60세 초과의 데이터는 존재하지 않음.
- age_band가 3인 60세의 데이터는 전체 2700개 중 192개(약 0.1%)에 불과하여 굉장히 불균형 문제가 심각.
문제3. 라벨 불균형

- 가장 많은 4번 class와 가장 적은 14번 class 간 차이가 4002개
- 특히 age에 관련된 라벨 불균형이 심각함
해결3-1. cutmix를 통해 부족한 라벨의 데이터를 upsampling


- 원래 cutmix는 dataset에서 불러온 이미지에 적용하는 방식. 따라서 원래 훈련 데이터의 분포를 따를 수 밖에 없다.
- 그렇다면 부족한 라벨에 대해서만 cutmix를 진행하여 데이터 증강의 효과를 볼 수 있을까? → 추가로 이미지를 생성하여 학습 데이터로 활용해보자!
- 2, 5, 8, 11, 14, 17 라벨(old age)에 대하여 cutmix 실행, 총 555개의 이미지를 생성하였음.
- 모든 이미지 데이터가 정면 사진임을 활용하여 width의 절반씩을 잘라 이미지를 합침
- cutmix loader를 통해 cutmix 데이터를 우선 학습하고, train loader를 통해 train data를 학습하는 식으로 진행
- loss값은 두 클래스에 관해서 0.5, 0.5씩 주었음
- 에폭 초반에만 학습하다 멈추는 방법과 에폭 전체에서 함께 학습하는 방법 모두 성능이 하락하거나 비슷했음.
- augmentation은 upsampling보다 전체 훈련 데이터의 분포를 다양화하는 역할로 활용해야 함 → 기존의 cutmix 학습 방법이 나을 수 있음.
해결 3-2. 라벨 재정의
- old 이미지가 부족하고 59세의 경우 old의 느낌이 많아 59세까지를 old class로 분류함.
- 실제 test score 성능 향상에 효과
해결 3-3. Focal Loss
- Hard Case에 높은 loss를 부여하여 라벨 불균형 해결에 적합
문제4. 잘못된 라벨링
- 남자임에도 여자로 라벨링된 것과 같은 오라벨링 데이터가 상당수 존재함.
- 남녀 또는 연령대 별 혼란을 불러 일으키는 데이터 이상치들이 다수 존재함.
해결4. data cleansing
- 먼저 전체 이미지 18,900장에 대한 전수 조사를 통해 약 20~30개의 오라벨링 데이터 검출 → 라벨 수정
- 성능에 영향을 미칠만한 outlier 50~60개 또한 검출(주로 남녀 및 연령대 혼란이 있는 데이터) → 논의를 통해 임의로 라벨 수정
4-2. 개인 실험
2023-04-13-12:21:39-Resnext50(submission1) 0.6544
Resnext50_32x4d, fc1, lr 0.0001, epoch 10, no augmentation, AdamW, CrossEntropyLoss, StepLR
- 낮은 에폭에도 좋은 성능
- 학습 후반부에는 val f1 score가 1에 수렴
- 그러나 test score에서 큰 gap→generalize 문제일지도?
2023-04-13-17:13:32-Resnext50(submission2) 0.7024
Resnext50_32x4d, fc2, lr 0.0001, epoch 10, no augmentation, AdamW, FocalLoss, StepLR(steps=10), early stopping(epochs 5)
- fc2: fc layer를 두 개의 층으로 구성
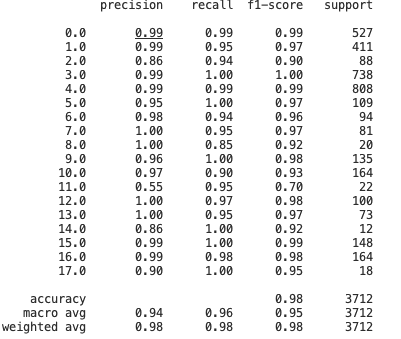
- 전반적으로 age가 old인 사람들에 대한 성능이 떨어짐
8, 11, 14, 17: old이고 mask가 incorrect, normal인 라벨에 대해서 낮은 f1 score
2: old이고 mask를 착용한 사람도 낮은 f1-score
- 에폭 3회만에 학습이 종료되는 걸로 보아 그 이상 학습하면 과적합 발생
→lr 줄이고 lr scheduler step size 1로 바꿈
- 대체로 에폭 10회 이내에 모델이 최적화되는 걸로 보아 generalization이 굉장히 중요한 task!
→ input data가 적고 패턴이 단조롭기 때문으로 추정
2023-04-14-22:30:11-Resnext50(submission4) 0.6878
Resnext50_32x4d, fc2, lr 0.0001, CenterCrop((320, 256)), StepLR(step size 1) transforms.RandomHorizontalFlip(), ToTensor(), Normalize(mean=mean, std=std), AdamW, FocalLoss, CosineAnnealingWarmRestarts(2, 2), epochs 20
- 높은 에폭수: 성능 하락
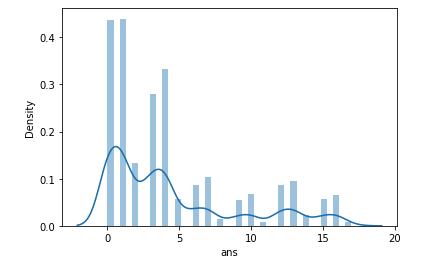

- submission4의 라벨의 분포를 보면 train data의 분포를 거의 그대로 따라간다. (2, 5번 라벨 적고 1, 4번 라벨 많음)
→과적합
- 많은 에폭으로 학습을 시킨 모델들은 validation score는 좋다. 그러나 test score에서 성능이 떨어진다
→test data와 train data 사이의 분포 차이가 있음을 추측해볼 수 있음.
→early stopping 필요
2023-04-15-20:53:11-Resnext50(submission5) 0.7352
Resnext50_32x4d, fc2, lr 0.0001, epoch 8, no augmentation, AdamW, FocalLoss, StepLR(step size 10), early stopping(patience = 2)

- fc layer에 dropout/relu 추가
- best model 저장 기준 val loss로 바꿈
- 낮은 에폭, early stopping, dropout/relu 효과가 컸음
→결국 과적합 방지가 관건임
→submission 4는 train data의 분포를 거의 그대로 따라가는 반면, submission 5는 train 데이터에 많이 없던 age가 old인 사람들에 대한 라벨이 많다. 특히 2, 5 등의 mask/old 라벨에 대해서 높은 답변율을 보이는 것을 알 수 있음
→ train/test 데이터 사이의 분포 차이 존재 → 부족한 label(old people)에 대해서도 균일한 학습이 필요하다
2023-04-18-17:06:52-Resnext50(submission12) 0.7598
Resnext50_32x4d, fc2, lr 0.0001, epoch 4, AdamW, FocalLoss, mike aug, old age>=59, K=10

- Stratified K-Fold
- 10개 모델을 학습하여 best 3개를 soft voting
→best1만 제출해봤는데 성능 떨어짐→확실히 앙상블이 일반화에 효과가 좋음
5. 모델 요약
5-1. Data Augmentation
중요 feature 추출
- Grayscale(3)
이번 분류 과제에서 주요 분류 class는 mask, age, gender 였음. 해당 class들의 주요feature는 color dependency가 전혀 없고, inference 시 다른 color에 대해서도 같은 class로 분류를 할 수 있게 하기 위해 원본 데이터를 3차원 흑백 이미지로 추가함.
- crop
분류 class들은 background에 dependency가 없으므로 최대한 배경을 제거하기 위해 주요 영역을 crop함. crop시 모든 데이터에 대해 인물들의 정보가 손실되지 않도록 최대한 보수적으로 영역을 설정하였음.
- Normalize
분류 class들 중 age 분류의 경우 전반적인 외곽선 보다는 texture 파악이 중요함.이번 데이터는 나이에 따라서 피부의 질감이 달라짐을 파악 할 수 있음. 또한 나이에 따라 피부의 명도가 달라짐을 확인 할 수 있음 하지만 Normalize 진행 시 각 이미지의 mean값을 빼주면 배경에 따라 피부의 명도가 달라지게 되고, 전체 image의 mean값을 빼주게 되더라도 age분류에 긍정적인 영항이 없게 됨. 또한 std를 나눠주는 과정에서 주름 등의 인물 feature 정보가 손실된다고 판단하여 Normalize를 진행하지 않음.
- RandomAutocontrast
이미지 전체에서 밝기와 대비를 조정하는 기법이다. 이러한 방식은 이미지에서 불규칙한 패턴이나 구조를 가진 작은 부분을 강조하는 효과를 줄 수 있다.
- RandomAdjustSharpen
이미지의 선명도를 높이기 위해서 적용되는 기법이다. 이미지에서 경계선을 강조하여 이미지를 더 선명하게 만들 수 있다. 특히 노인들의 얼굴을 보면 많은 주름이 보일 수 있다. 이런한 특징을 고려하여 sharpen기술을 활용하여 얼굴 주름 부분을 더욱 강조하고, 이를 통해 모델이 노인 얼굴을 더욱 정확하게 학습할 수 있도록 하였다.
다양성 부여
- RandomApply
다양성 부여를 위한 모든 augmentation은 모델이 원본 이미지도 train 할 수 있도록 RandomApply를 적용함.
- RandomHorizontalFlip
주요 정보를 손실하지 않고 다양성을 부여하기 위해 수평방향으로 flip을 진행
- RandomCrop
주요 정보를 손실하지 않고 다양성을 부여하기 위해 보수적인 size의 crop진행
- RandomPerspective
정면을 바라보고 있지 않은 데이터를 보충하는 역할을 할 것이라 예상했으나 오히려 성능이 안좋아짐.
- ColorJitter
이미지의 밝기 값과 색의 다양성을 주려고 했으나 성능이 안좋아짐.
- Gray-Scale 변환 후 얼굴 전체, 이목구비, 옷스타일 정보를 3채널에 저장하는 Transform
데이터를 다양한 각도로 학습시킬 수 있는 방법이다. 성별과 나이를 구분할 때 얼굴뿐만 아니라, 옷 스타일, 헤어 스타일도 중요한 정보가 될 수 있다고 생각했다. 따라서 Gray-Scale의 이미지를 얼굴 전체, 이목구비, 옷 스타일의 모습으로 각각 crop해서 3개의 채널로 concat하여 모델이 학습할 수 있도록 하였다.
5-2. 학습 환경
Optimizer: AdamW
Loss: Focal Loss
Learning rate: 0.0001
Learning Scheduler: X
5-3. 앙상블
첫 번째 실험
- ResNeXt50 단일 모델을 Stratified-K-Fold(K=10)로 학습시킨 모델 중 best 3개 모델을 앙상블
→ F1-Score: 0.7598 Acc: 81.3651 달성
두 번째 실험
- ResNeSt50 단일 모델을 Stratified-K-Fold(K=5)로 학습시킨 모델을 사용
- 다양성을 위해 Age Dataset을 58세 이상, 58세 이상, 59세 이상을 Old로 구성한 모델을 앙상블 함.
→ F1-Score: 0.7619 Acc: 80.7778 달성
세 번째 실험
- 상기 언급한 모델 6개를 합쳐서 soft-voting 방법으로 앙상블
→ F1-Score: 0.7625 Acc: 81.2063 달성
최종 Ensemble
backbone dataset augmentation K option
| backbone | dataset | augmentation | K | |
| Resnext50 | 수정 전 data | CustomAugmentation | 10 | |
| Resnext50 | 수정 전 data | CustomAugmentation | 10 | |
| Resnext50 | 수정 전 data | CustomAugmentation | 0(no validation) | |
| Resnest50 | 수정 후 data | CustomAugmentation | 5 | |
| Resnest50 | 수정 후 data | CustomAugmentation | 5 | |
| Resnest50 | 수정 후 data | CustomAugmentation | 5 |
→ F1-Score: 0.7659 Acc: 81.556 달성
5-4. 대회 결과


Public 5등, f1 socre 0.7660 → Private 2등, f1 score 0.7668
대부분의 팀이 private score가 떨어진 것에 비해 저희 팀은 private score가 상승하며 순위가 올랐습니다. 아무래도 학습 환경을 통일하지 않고 다양하게 실험적으로 접근하며 최적의 모델을 찾다보니, 앙상블에서 일반화 효과를 극대화할 수 있었다고 생각합니다.
6. 개인 회고
학습 목표를 달성하기 위해 시도한 점
이번 프로젝트의 목표는 사용자의 얼굴을 촬영한 이미지에서 사용자의 마스크 착용 여부, 나이, 성별을 추론하는 것이었습니다. 이를 위해서 EDA, 이미지 전처리와 모델 학습 등을 진행하였습니다.
- EDA
본격적인 모델링에 들어가기 전, 데이터에 대한 이해를 위해 EDA를 진행하였습니다. feature 중 age가 old인 사람이 전체 데이터의 약 0.1% 수준이라는 점과 마스크를 착용한 사진이 착용하지 않았거나 잘못 착용한 사진보다 5배 많다는 점을 발견할 수 있었습니다.
- 신뢰할 수 있는 validation
학습 데이터에서 단순히 train과 validation을 나누었을 때, 모델이 validation에서는 accuracy와 f1 score 모두 1에 가까운 성능을 보였습니다. 그러나 test에서는 f1 score 0.65 정도의 현저히 떨어지는 성능을 보이는 것을 관찰할 수 있었습니다.
이로부터 추측할 수 있는 부분은 두 가지 입니다. 학습 데이터와과 테스트 데이터의 분포가 다를 수 있다는 점, 그리고 라벨 불균형 문제가 심각하여 단순 split으로 나눈 훈련 데이터에서 특정 라벨에 대한 과적합이 발생할 수 있다는 점입니다. 즉 일반적인 split이 아닌 신뢰성 있는 validation 기준이 필요했습니다.
이를 해결하기 위해 Stratified K-Fold에서 K를 10으로 늘려 안정적인 학습을 진행하였고, 그중 accuracy가 가장 높은 3개의 모델을 앙상블하여 활용하였습니다. 또한 실험적으로 에폭 3회 내외에서 validation loss가 크게 상승할 때 과적합이 발생하는 점을 발견할 수 있었습니다. 이 점에서 착안하여 에폭을 4회 이내로 줄이고 early stoping(patience=1)를 적용하여 자체적인 validation 기준을 만들었습니다.
- 과적합
모델을 많이 학습시킬 수록 validation loss가 줄어들길래 실제 성능이 향상되는 줄로 알았는데, 에폭 5회, 20회 모두 에폭 3회보다 성능이 하락했습니다. 에폭 20회의 추론 분포를 확인해보니 학습 데이터의 분포를 그대로 따라가는 반면, 에폭 3회는 학습 데이터에 적던 2번이나 5번 라벨에 대해서도 높은 답변율을 보였습니다.
이를 통해 학습 데이터와 테스트 데이터 간의 분포 차이가 있음을 확인하였습니다. 그래서 과적합 방지를 위해 에폭을 4회 이내로 줄이고 early stopping, dropout, weight decay 등의 방법론을 적용하였습니다.
구현 방식
- resnext50 backbone + fc layer(dropout, batchnormalization, relu) 18개 추론 모델
이미지 분류 문제에 최적화된 모델을 리서치 하던 중 resnext50을 발견하여 backbone으로 활용하였습니다. 처음에는 한 개의 출력층만 쌓아 2048개의 노드를 18개로 연결하였는데, 하나의 층을 더 쌓고 dropout과 relu를 적용하여 큰 성능 향상을 보았습니다. 이를 통해 과적합 방지가 이번 task의 핵심임을 다시금 확인하였습니다.
- resnext50 backbone + fc layer(dropout, batchnormalization, relu) mask, gender, age 모델 앙상블
단일모델로 18개의 라벨을 추론하는 것이 아니라 마스크, 성별, 나이라는 세 개의 과제로 나눠서 세 개의 모델을 학습시켰습니다. 단순히 더해서 라벨을 추론하는 방법과 선형 모델에 넣어 학습시키는 방법 모두 성능 하락이 있어 이후로 활용하지는 않았습니다.
- AdamW
Adam은 빠른 속도로 많이 쓰이는 optimizer이지만, 일반화 성능이 떨어진다고 한다. 그래서 weight decay를 추가한 AdamW를 활용하여 과적합을 방지하고 일반화 성능을 높였다.
- cutmix
학습 데이터가 현저히 적기 때문에, 데이터 증강 기법으로 cutmix를 활용해보려 했습니다. 특히 라벨 불균형 문제를 해결하고자 부족한 old 라벨에 대해서만 데이터를 증강시켰습니다. 증강 데이터와 원본 데이터를 섞어서 함께 활용하고자 했으나 pytorch 구현의 문제로 우선 증강 데이터를 학습시킨 뒤 원본 데이터를 학습시키는 방향으로 진행했습니다.
결론적으로 증강 데이터에 대하여 모델이 biased되어 성능이 악화되는 결과를 낳았습니다. 이 점에서 데이터 증강 기법은 원본 데이터의 분포를 다양화하는 데 활용되어야 하는 것이지, 설계자의 의도대로 데이터의 분포를 변경하는 데 쓰려고 하면 오히려 불안정한 학습을 초래할 수 있다는 점을 배웠습니다.
- 앙상블
Stratified K-Fold에서 accuracy가 제일 높은 top 3 모델로 soft voting하였고 성능이 크게 향상하였습니다. 추가적으로 성능을 높일 길을 찾다가 앙상블은 다른 분포의 모델을 활용할 때 성능 발전이 크다는 내용을 보았습니다.
그래서 top3 중 분포가 비슷한 2개 중 1개를 빼고, 대신 validation 없이 에폭 2번으로 학습시킨 모델을 포함시켰습니다. 최종적으로 제가 설계한 모델 3개와 팀원이 설계한 모델 3개를 soft voting하였습니다. public 기준 f1 0.7659, private에서는 0.7668로 score 향상을 보이며 높은 일반화 성능을 보였습니다.
저희는 팀원끼리 학습환경을 통일하지 않았는데, 오히려 다양한 세팅으로 학습시키는 방법이 일반화에 도움이 되었다는 생각이 들었습니다.
마주한 한계/아쉬웠던 점
- cutmix
cutmix를 전체 데이터셋에 대해서 적용해보고 싶었는데, 촉박한 시간 문제로 진행해보지 못한 점이 아쉽습니다. 다음 프로젝트에서는 원래 방식대로의 cutmix를 구현해보고 성능 변화를 확인하고 싶습니다.
- 협업 환경
협업 환경을 통일하지 않은 상태로 각자의 코드 가지고 프로젝트를 진행했는데, 후반부에 코드를 교환할 일이 있을 때 제 코드와 호환이 되도록 수정해야 해서 불편했습니다. 다만 저희 팀의 시너지는 다양한 학습환경에서 왔다고 생각하여 전체 학습 세팅을 맞출 필요는 없을 것 같습니다. 다음부터는 기본 베이스라인 코드를 통일하여 구현 방식을 맞춤으로써 코드를 복붙해도 이용하기 쉽도록 진행하고 싶습니다.
- config
발표를 들어보니 yaml config 파일을 통해 창을 닫아도 학습이 진행되도록 구현한 팀이 있었습니다. 저는 매번 코드를 실행하고 노트북을 실행하고 있어야 해서 불편한 점이 많았는데, 다음부터는 yaml 파일을 활용해 보아야 겠습니다.
'Naver Boostcamp' 카테고리의 다른 글
| 글자 검출 프로젝트 대회 (0) | 2023.08.01 |
|---|---|
| 재활용 품목 분류를 위한 Object Detection 대회 (0) | 2023.08.01 |
| [Pytorch 활용하기] Multi-GPU 학습 (0) | 2023.04.09 |
| [Pytorch 구조 학습하기2] 모델 불러오기 & transfer learning (0) | 2023.04.09 |
| [Pytorch 구조 학습하기]Dataset과 DataLoader (0) | 2023.03.21 |